

Databricks SQL: Novidades em Otimizações de AI, Federação de Lakehouse e mais para BI Empresarial
Descubra as últimas inovações do Databricks SQL: otimizações AI, federação de lakehouse e mais. Saiba como impulsionar seu BI empresarial com eficiência e performance.
Otimização impulsionada por AI: Potencializando Seu Lakehouse
Acreditamos em maximizar o potencial do seu lakehouse e, por isso, estendemos nossa liderança em cargas ETL e uso de AI. Agora, o Databricks SQL oferece performance líder na indústria para suas análises exploratórias de dados (EDA) e cargas de trabalho de BI, com economia de custos notáveis – sem ajustes manuais.
Reduza o Custo Total de Propriedade

Diga adeus à criação manual de índices. Com a I/O Preditiva para leituras (GA) e atualizações (Visualização Pública), o Databricks SQL analisa padrões históricos de leitura e gravação para construir índices e otimizar cargas de trabalho de forma inteligente. Clientes antecipados obtiveram uma melhoria notável de 35x na eficiência de busca por ponto, aumentos impressionantes de desempenho de 2-6x para operações MERGE e 2-10x para operações DELETE.
Através das Otimizações Preditivas (Visualização Pública), o Databricks otimiza automaticamente tamanhos de arquivo e clustering, executando comandos como OPTIMIZE, VACUUM, ANALYZE e CLUSTERING por você. A Anker Innovations, por exemplo, obteve um aumento de 2,2x no desempenho de consultas, com economia de 50% nos custos de armazenamento.
“Otimizações Preditivas do Databricks otimizaram de forma inteligente nosso armazenamento Unity Catalog, economizando 50% nos custos de armazenamento anuais, ao mesmo tempo que aceleraram nossas consultas em >2x. Aprendeu a priorizar nossas tabelas maiores e mais acessadas. E fez tudo isso automaticamente, poupando tempo valioso para nossa equipe.”
— Anker Innovations

Gestão Inteligente de Cargas de Trabalho: Eficiência e Equilíbrio
Cansado de gerenciar armazéns diferentes para cargas de trabalho menores e maiores ou ajustar parâmetros de escala? A Gestão Inteligente de Cargas de Trabalho oferece recursos que mantêm consultas rápidas sem comprometer custos. Analisando padrões em tempo real, garante que suas cargas de trabalho tenham a quantidade ideal de recursos para executar declarações SQL sem interromper consultas em andamento.
Com otimizações impulsionadas por AI, o Databricks SQL oferece TCO e desempenho líderes do setor para qualquer tipo de carga de trabalho, sem ajustes manuais necessários. Saiba mais sobre as visualizações de otimização disponíveis assistindo ao keynote de Reynold Xin e ao Databricks SQL Serverless Under the Hood: Como Usamos ML para Obter a Melhor Relação Preço/Desempenho no Data+AI Summit.
Desbloqueie Dados Isolados com a Federação de Lakehouse
As organizações de hoje enfrentam desafios ao descobrir, governar e consultar fontes de dados isoladas em sistemas fragmentados. Com a Federação de Lakehouse, equipes de dados podem usar o Databricks SQL para descobrir, consultar e gerenciar dados em plataformas externas, incluindo MySQL, PostgreSQL, Amazon Redshift, Snowflake, Azure SQL Database, Azure Synapse, Google’s BigQuery (em breve) e mais.
Além disso, a Federação de Lakehouse se integra perfeitamente a recursos avançados do Unity Catalog ao acessar fontes de dados externas de dentro do Databricks. Reforce a segurança em nível de linha e coluna para restringir o acesso a informações sensíveis. Alavanque a linhagem de dados para rastrear a origem dos seus dados e garantir qualidade e conformidade dos dados. Para organizar e gerenciar ativos de dados, marque facilmente ativos do catálogo federado para uma descoberta simples de dados.
Finalmente, para acelerar transformações complexas ou junções cruzadas em fontes federadas, a Federação de Lakehouse suporta Visualizações Materializadas para melhores latências de consulta.
A Federação de Lakehouse está em Visualização Pública hoje. Para mais detalhes, assista à nossa sessão dedicada Federação de Lakehouse: Acesso e Governança de Fontes de Dados Externos do Unity Catalog no Data+AI Summit.
Desenvolva no Lakehouse com a API de Execução de Declarações SQL
A API de Execução de Declarações SQL permite o acesso ao seu armazém Databricks SQL por meio de uma API REST para consultar e obter resultados. Com estruturas HTTP disponíveis para quase todas as linguagens de programação, você pode se conectar facilmente a uma variedade de aplicativos e plataformas diretamente a um Armazém Databricks SQL.
A API de Execução de Declarações SQL do Databricks SQL está disponível nas camadas Premium e Enterprise do Databricks. Saiba mais assistindo à nossa sessão, seguindo nosso tutorial (AWS | Azure), lendo a documentação (AWS | Azure) ou verificando nosso repositório de exemplos de código.
Otimize seu processamento de dados com Streaming Tables, Materialized Views e DB SQL em Workflows
Com Streaming Tables, Materialized Views e DB SQL em Workflows, qualquer usuário de SQL agora pode aplicar as melhores práticas de engenharia de dados ao processar dados. Ingestão, transformação, orquestração e análise eficientes de dados com apenas algumas linhas de SQL.
Streaming Tables são ideais para trazer dados para tabelas “bronze”. Com uma única declaração SQL, é possível fazer a ingestão escalável de dados de várias fontes, como armazenamento em nuvem (S3, ADLS, GCS), barramentos de mensagens (EventHub, Kafka, Kinesis) e muito mais. Essa ingestão ocorre de forma incremental, possibilitando pipelines de baixa latência e baixo custo, sem a necessidade de gerenciar infraestrutura complexa.
CREATE STREAMING TABLE web_clicks
AS
SELECT *
FROM STREAM
read_files('s3://mybucket')
Materialized Views reduzem custos e melhoram a latência da consulta pré-computando consultas lentas e cálculos frequentemente usados, e são atualizados de forma incremental para melhorar a latência geral. Em um contexto de engenharia de dados, eles são usados para transformar dados. Mas também são valiosos para equipes de análise em um contexto de armazenamento de dados, pois podem ser usados para (1) acelerar consultas de usuários finais e painéis de BI e (2) compartilhar dados com segurança. Com apenas quatro linhas de código, qualquer usuário pode criar uma visualização materializada para processamento de dados eficiente.
CREATE MATERIALIZED VIEW customer_orders
AS
SELECT
customers.name,
sum(orders.amount),
orders.orderdate
FROM orders
LEFT JOIN customers ON
orders.custkey = customers.c_custkey
GROUP BY
name,
orderdate;
Precisa de orquestração com DB SQL? Workflows agora permite agendar consultas SQL, painéis e alertas. Gerencie facilmente dependências complexas entre tarefas e monitore execuções de trabalhos anteriores com a intuitiva interface de Workflows ou via API.
Streaming Tables e Materialized Views estão agora em visualização pública. Para saber mais, leia nossa postagem no blog dedicada. Para se inscrever na visualização pública para ambos, inscreva-se neste formulário. O Workflows no DB SQL agora está disponível e você pode saber mais lendo a documentação (AWS | Azure).
Databricks Assistant e LakehouseIQ: Escreva SQL Melhor e Mais Rápido com Linguagem Natural
O Databricks Assistant é um assistente de AI com contexto incorporado em Notebooks Databricks e no SQL Editor. O Databricks Assistant pode transformar uma pergunta em linguagem natural em uma consulta SQL sugerida para responder a essa pergunta. Ao tentar entender uma consulta complexa, os usuários podem pedir ao Assistente que a explique usando linguagem natural, permitindo que qualquer pessoa entenda a lógica por trás dos resultados da consulta.
Nos bastidores, o Databricks Assistant é alimentado por uma inteligência artificial chamada LakehouseIQ. LakehouseIQ entende sinais como esquemas, popularidade, linhagem, comentários e documentos para melhorar a busca e as experiências de AI no Databricks. LakehouseIQ aprimorará várias experiências de produtos existentes com resultados mais precisos e relevantes, incluindo Pesquisa, Ajuda e Databricks Assistant.
LakehouseIQ
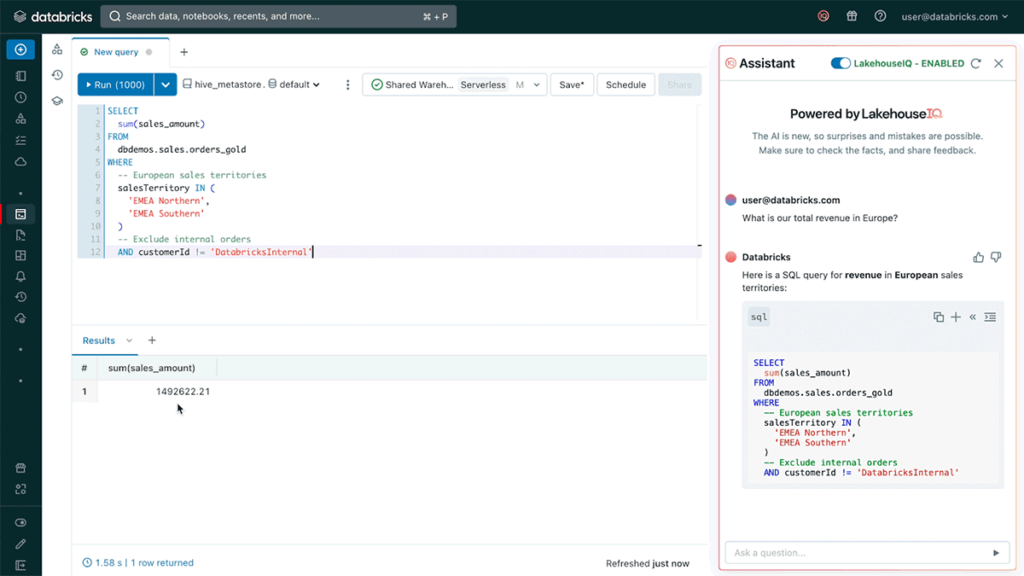
O LakehouseIQ está em desenvolvimento e estará disponível ainda este ano. O Databricks Assistant estará disponível para visualização pública nas próximas semanas. Com o tempo, integraremos o Assistente ao LakehouseIQ para fornecer sugestões mais precisas e personalizadas com base nos dados da sua empresa.
Gerencie seu Data Warehouse com Confiança
Administradores e equipes de TI precisam de ferramentas para entender o uso do data warehouse. Com System Tables, Live Query Profile e Statement Timeouts, os administradores podem monitorar e resolver problemas quando ocorrem, garantindo que seu data warehouse funcione de maneira eficiente.
Ganhe visibilidade e insights mais profundos sobre seu ambiente SQL com as System Tables. As System Tables são tabelas fornecidas pela Databricks que contêm informações sobre execuções de declarações anteriores, custos, linhagem e muito mais. Explore metadados e métricas de uso para responder a perguntas como “Quais declarações foram executadas e por quem?”, “Como e quando meus data warehouses foram dimensionados?” e “Pelo que fui cobrado?”. Como as System Tables estão integradas ao Databricks, você tem acesso a recursos nativos como alertas SQL e painéis SQL para automatizar o processo de monitoramento e alerta.
Atualmente, existem três System Tables em visualização pública: Audit Logs, Billable Usage System Table e Lineage System Table (AWS | Azure). Mais system tables para eventos de data warehouse e histórico de declarações estão chegando em breve.
Por exemplo, para calcular as DBUs mensais usadas por SKU, você pode consultar as System Tables de uso faturável.
SELECT sku_name, usage_date, sum(usage_quantity) as `DBUs`
FROM system.billing.usage
WHERE
month(usage_date) = month(NOW())
AND year(usage_date) = year(NOW())
GROUP BY sku_name, usage_date
Com o Live Query Profile, os usuários obtêm insights em tempo real sobre o desempenho da consulta para otimizar cargas de trabalho conforme necessário. Visualize planos de execução de consultas e avalie a execução de tarefas de consulta ao vivo para corrigir erros comuns de SQL, como junções explosivas ou varreduras de tabela completas. O Live Query Profile permite garantir que as consultas em execução no seu data warehouse sejam otimizadas e executadas de forma eficiente. Saiba mais lendo a documentação (AWS | Azure).
Procurando controles automatizados? Os Statement Timeouts permitem definir um tempo limite personalizado para o workspace ou nível de consulta. Se o tempo de execução de uma consulta exceder o limite de tempo, a consulta será interrompida automaticamente. Saiba mais lendo a documentação (AWS | Azure).
Experiências Compelentes no DBSQL
No último ano, trabalhamos arduamente para adicionar novas experiências inovadoras ao Databricks SQL. Estamos animados em anunciar novos recursos que colocam o poder da AI nas mãos dos usuários de SQL, como habilitar SQL warehouses em toda a plataforma Databricks; introduzir uma nova geração de painéis de SQL; e trazer o poder do Python para o Databricks SQL.
Democratize a análise de dados não estruturados com Funções de AI
Com as Funções de AI, o DB SQL traz o poder da AI para o armazém de SQL. Use facilmente o potencial de dados não estruturados realizando tarefas como análise de sentimentos, classificação de texto, sumarização, tradução e muito mais. Analistas de dados podem aplicar modelos de AI por meio de autoatendimento, enquanto engenheiros de dados podem criar pipelines habilitados para AI de forma independente.
Usar Funções de AI é simples. Por exemplo, considere um cenário em que um usuário deseja classificar o sentimento de alguns artigos em Frustrado, Feliz, Neutro ou Satisfeito.
-- create a udf for sentiment classification
CREATE FUNCTION classify_sentiment(text STRING)
RETURNS STRING
RETURN ai_query(
'Dolly', -- the name of the model serving endpoint
named_struct(
'prompt',
CONCAT('Classify the following text into one of four categories [Frustrated, Happy, Neutral, Satisfied]:\n',
text),
'temperature', 0.5),
'returnType', 'STRING');
-- use the udf
SELECT classify_sentiment(text) AS sentiment
FROM reviews;
As Funções de AI estão agora em Visualização Pública. Para se inscrever na Prévia, preencha o formulário aqui. Para saber mais, você também pode ler nossa postagem detalhada no blog ou revisar a documentação (AWS | Azure).
Leve o poder dos armazéns de SQL para notebooks
Os armazéns de SQL do Databricks agora estão em visualização pública em notebooks, combinando a flexibilidade de notebooks com o desempenho e o TCO dos armazéns de SQL Serverless e Pro do Databricks. Para habilitar os armazéns de SQL em notebooks, basta selecionar um armazém de SQL disponível no menu suspenso de computação dos notebooks.
Encontre e compartilhe insights com uma nova geração de painéis
Descubra uma experiência de painel renovada diretamente no Lakehouse. Os usuários podem selecionar um conjunto de dados desejado e criar visualizações impressionantes com uma experiência opcional de SQL. Diga adeus à gestão de consultas e objetos de painel separados – um modelo de conteúdo tudo-em-um simplifica as permissões e o processo de gerenciamento. Finalmente, publique um painel para toda a organização, para que qualquer usuário autenticado no provedor de identidade possa acessar o painel por meio de um link da web seguro, mesmo sem acesso ao Databricks.
Os novos Painéis Databricks SQL estão atualmente em Visualização Privada. Entre em contato com a sua equipe de conta para saber mais.
Aproveite a flexibilidade do Python no SQL
Traga a flexibilidade do Python para o Databricks SQL com Funções Definidas pelo Usuário (UDFs) em Python. Integre modelos de machine learning ou aplique lógica personalizada de redação para processamento e análise de dados, chamando funções personalizadas de Python diretamente da sua consulta SQL. UDFs são funções reutilizáveis, permitindo que você aplique processamentos consistentes aos seus pipelines de dados e análises.
Por exemplo, para redigir endereços de e-mail e números de telefone de um arquivo, considere a seguinte instrução CREATE FUNCTION.
CREATE FUNCTION redact(a STRING)
RETURNS STRING
LANGUAGE PYTHON
AS $$
import json
keys = ["email", "phone"]
obj = json.loads(a)
for k in obj:
if k in keys:
obj[k] = "REDACTED"
return json.dumps(obj)
$$;
Disclaimer: Este artigo e imagens foram extraídos do site oficial Databricks, confira a postagem na integra: What’s new with Databricks SQL? | Databricks Blog





